مقدمه
در این مقاله، سعی خواهیم کرد توضیحی راجع به سؤالات زیر ارائه دهیم:
1- Node Embedding چیست؟
2- چگونه میتوان Node Embedding را تولید کرد؟
3- در کدام مواقع میتوان از Node Embedding استفاده کرد؟
گراف ها

گرافها شامل گرهها(node) و یالها(ارتباطهای بین گرهها-edge) هستند.
در شبکههای اجتماعی، گرهها میتوانند نمایانگر کاربران باشند و پیوندها بین آنها میتوانند دوستیها را نشان دهند.
یک مسأله جالبی که میتوان با استفاده از گرافها انجام داد، پیشبینی این است که کدام توئیتها در توییتر از رباتها و کدام توئیتها از کاربران اصلی است. چگونه میتوان این کار را انجام داد؟ خب، با ما همراه باشید و ایدهای از اینکه چگونه ممکن است انجام شود، خواهید گرفت.
یادگیری ماشین با گراف ها – دانشگاه استنفورد
Node Embedding چیستند؟
با توجه به دیکشنری انگلیسی، کلمه “تعبیر دادن” به معنی تثبیت چیزی در یک ماده یا جسم جامد است. در مورد گرافها، این به معنای نگاشت کل گراف در فضای چند بعدی N-بعدی است. به نمونه زیر نگاهی بیندازید. در این نمونه، تمامی گرهها را در فضای دو بعدی نگاشت کردهایم. حالا، واضح است که دو خوشه (یا اجتماع) در گراف وجود دارند. برای ما انسانها، شناسایی خوشهها در فضای دو بعدی آسانتر است. در این نمونه، همچنین آسان است که خوشهها را فقط از قالب گراف شناسایی کنیم، اما تصور کنید که گراف 1000 گره داشته باشد – مسائل دیگر آنقدر ساده نیستند.
علاوه بر این، برای یک کامپیوتر، کار با Node Embedding (بردارهایی از اعداد) آسانتر است، زیرا محاسبه شباهت (نزدیکی در فضا) دو گره از Embedding در فضای N-بعدی، نسبت به محاسبه آن فقط از گراف آسانتر است. از سوی دیگر، روش مناسبی برای محاسبه نزدیکی دو گره فقط از گراف وجود ندارد. میتوانید از چیزی شبیه الگوریتم کوتاهترین مسیر استفاده کنید، اما خود آن به تنهایی کافی نمیباشد. با بردارها، کار آسانتر است. معیار بیشتر استفاده شده به نام شباهت کسینوسی(cosine similarity) است.
اکنون ما چیزی داریم که یک کامپیوتر میتواند با آن کار کند:

حالا که میدانیم Node Embedding چیستند، اما برای چه چیزهایی از آنها استفاده میکنیم؟
یادگیری ماشین با نظارت، یک زیرمجموعه از یادگیری ماشین است که الگوریتمها سعی میکنند از دادهها یاد بگیرند. دادهها توسط جفتهای ورودی-خروجی نمایش داده میشوند، به عنوان مثال [2] -> 2، [1] -> 1. مدل ما سعی میکند به گونهای از دادهها یاد بگیرد که ورودیها را به خروجیهای صحیح نگاشت کند. در مثال ما ([2] -> 2، [1] -> 1)، مدل سعی میکند تابع y=x را یاد بگیرد. در اینجا، برای مدل آسان است که نگاشت ورودی-خروجی را یاد بگیرد، اما تصور کنید که در یک مسئله بسیاری از نقاط مختلف فضای ورودی به یک مقدار خروجی نگاشت شوند. به همین دلیل، نمیتوانیم به طور مستقیم یک الگوریتم یادگیری ماشین را بر روی جفتهای ورودی-خروجی اعمال کنیم، بلکه ابتدا باید مجموعهای از ویژگیهای اطلاعاتی، تمییزدهنده و مستقل را در میان نقاط دادههای ورودی پیدا کنیم. پیدا کردن چنین ویژگیهایی معمولاً یک وظیفه پیچیده است.
در مسائل پیشبینی در شبکهها، باید همان کار را برای گرهها و یالها انجام دهیم. یک راه حل معمول شامل طراحی ویژگیهای خاص به دست آمده از دانش تخصصی است. حتی اگر تلاش زیادی را برای طراحی ویژگیها انجام دهید، این ویژگیها معمولاً برای وظایف خاصی طراحی میشوند و به طور کلی بر روی وظایف پیشبینی مختلف تعمیمپذیر نیستند.
ما میخواهیم الگوریتم خود را به طور مستقل از وظیفهی پیشبینی در آینده طراحی کنیم و اینکه نمایشها به صورت کاملاً بینظارت قابل یادگیری باشند. اینجاست که Node Embedding وارد صحنه میشوند.
ما الگوریتم خود را به یادگیری Embedding آموزش میدهیم و سپس میتوانیم این Embedding ها را در هر یک از کاربردهای زیر استفاده کنیم، یکی از آنها تشخیص رباتهای توییتر است. بیایید به بررسی جزئیات بپردازیم.
چگونه می توان Node Embedding را تولید کرد؟
پژوهشگران این روشها را به سه دسته عمده تقسیم کردهاند:
1- مبتنی بر فاکتوریزاسیون (Factorization based)
الگوریتمهای مبتنی بر فاکتوریزاسیون، ارتباطات بین گرهها را به صورت یک ماتریس نمایش میدهند و این ماتریس را فاکتوریزه کرده وابستگیهای بین گرهها را استخراج میکنند. در یکی از این روشها که با نام Local Linear Embedding شناخته میشود، فرض میشود که هر گره یک ترکیب خطی از همسایگان خود است، بنابراین الگوریتم سعی میکند Node Embedding را به عنوان یک ترکیب خطی از نمایشگرهای همسایگان آن نمایش دهد. این مانند مثالی است که در دوران دبیرستان بایستی یک بردار را به عنوان ترکیب خطی از دو بردار دیگر نمایش دهید. اما اینجا ممکن است چندین بردار داشته باشید و آنها پیچیدهتر هستند.
در این روشها، یک ماتریس فاکتوریزه شده از گراف برای تولید نمایشگرها استفاده میشود. روشهایی مانند استفاده از روش Singular Value Decomposition (SVD) و Principal Component Analysis (PCA) در این دسته قرار میگیرند.
2- مبتنی بر گردش تصادفی (Random Walk based)
از روشهای گردش تصادفی برای تولید (نمونهبرداری) همسایگیهای شبکه برای گرهها استفاده میکنند. برای هر گره، ما با انتخاب روشی (بسته به روش، میتواند تصادفی باشد یا ممکن است احتمالاتی شامل شود)، گره بعدی ما در مسیر گردش را انتخاب میکنیم. در تصویر زیر میتوانید نحوه آن را مشاهده کنید.
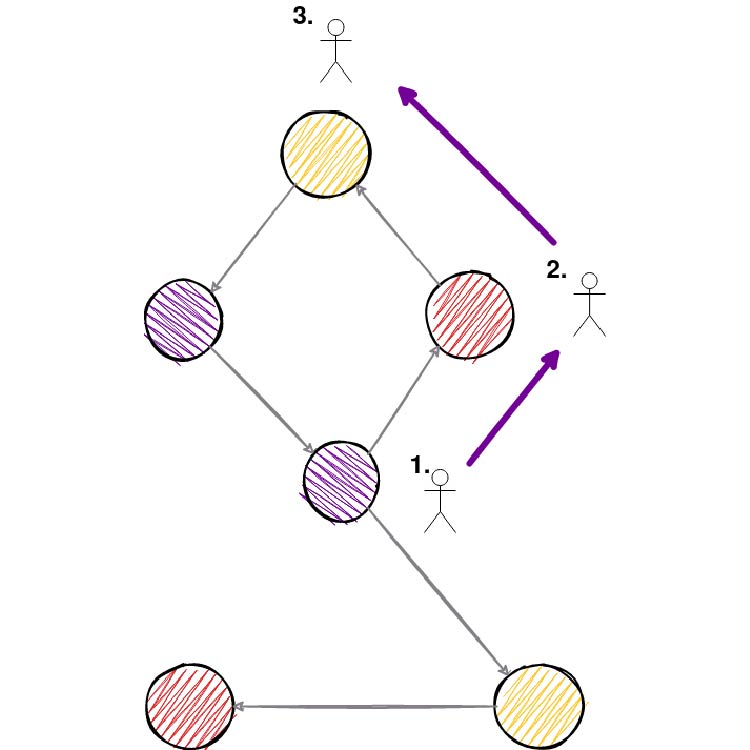
از روشهای گردش تصادفی برای تولید (نمونهبرداری) همسایگیهای شبکه برای گرهها استفاده میکنند. برای هر گره، ما با انتخاب روشی (بسته به روش، میتواند تصادفی باشد یا ممکن است احتمالاتی شامل شود)، گره بعدی ما در مسیر گردش را انتخاب میکنیم. در تصویر زیر میتوانید نحوه آن را مشاهده کنید.
حداکثر طول گردش تصادفی قبل از این فرآیند نمونهبرداری گردش مشخص میشود و برای هر گره، ما N گردش تصادفی تولید میکنیم. این کار باعث ایجاد یک همسایگی شبکه برای گره میشود. حال هدف ما این است که یک گره را با گرههای در همسایگی خود به حد امکان شبیهسازی کنیم.
و دوباره این سوال خسته کننده: چرا میخوایم ازشون استفاده کنیم؟
به نظر میرسد که این روش در یک حوزه دیگر به نام پردازش زبان طبیعی که با کلمات و سندها سر و کار دارد، بسیار موفق بوده است. در این حوزه، هدف ما پیدا کردن کلمات مشابه است. به عنوان مثال، کلمات ” smart” و “intelligent” باید کلمات مشابهی باشند. این روش در پردازش زبان طبیعی با نام word2vec شناخته میشود. کلماتی که در یک زمینه مشابه ظاهر میشوند (کلمات قبل یا بعد از آن کلمه)، باید مشابه باشند. خوشبختانه، همین مسئله برای گرهها نیز صدق میکند. گرههایی که در یک زمینه مشابه ظاهر میشوند (گردشهای تصادفی نمونهبرداری شده)، باید مشابه باشند. فرآیند ما در نمونهبرداری گردش برای ایجاد مجموعه دادهای استفاده میشود که در آن سعی میکنیم نمایشگرهای گره را به حد امکان مشابه سازی کنیم. و همین است!!!! مجموعه داده در روشهای word2vec هر جمله از یک سند است، و به طور مشابه برای ما، هر گردش تصادفی گراف نمونهبرداری شده است.
3- مبتنی بر یادگیری عمیق (Deep Learning based):
تحقیقات روزافزون در زمینه یادگیری عمیق منجر به استفاده از روشهای مبتنی بر شبکههای عصبی عمیق بر روی گرافها شده است. با استفاده از یادگیری عمیق، آسانتر است که ساختارهای غیرخطی را مدل کنیم، بنابراین از شبکههای عصبی عمیق اتوانکدرها برای کاهش بعد استفاده شده است. چند روش معروف در این زمینه به نام Structural Deep Network Embedding (SDNE) و Deep Neural Networks for Learning Graph Representations (DNGR) وجود دارند، بنابراین لطفاً آنها را بررسی کنید.
Node Embedding کجا قابل استفاده هستند؟
میدانیم که گرافها به طور طبیعی در صحنههای مختلف دنیای واقعی مانند شبکههای اجتماعی (علوم اجتماعی)، شبکههای همدید کلمات (زبانشناسی)، شبکههای تعاملی (مانند تعاملات پروتئین-پروتئین در زیستشناسی) و غیره رخ میدهند. Node Embedding ، مدلسازی تعاملات بین موجودیتها به صورت گراف، به محققان امکان میدهد تا شبکههای مختلف را به صورت سیستماتیک درک کنند. به عنوان مثال، شبکههای اجتماعی برای کاربردهایی مانند پیشنهاد دوستی یا محتوا، و همچنین برای تبلیغات استفاده شدهاند.
1- طبقهبندی گرهها(Node classification)
هدف طبقهبندی گرهها، تعیین برچسب گرهها (یا رئوس) بر اساس گرههای دیگری که برچسب دار هستند و توپولوژی شبکه است. اغلب در شبکهها، تنها یک بخش کوچکی از گرهها برچسبگذاری شده است. در شبکههای اجتماعی، برچسبها ممکن است به علاقهها، باورها یا ویژگیهای جمعیتی اشاره کنند، در حالی که برچسبهای موجودیتها در شبکههای زیستشناسی ممکن است بر اساس عملکرد آنها باشد. به عنوان مثال، ما برخی از دادهها را داریم که محققان با دقت بالا نقش عملکردی پروتئینهای خاص را در سیستم مورد نظر خود تعیین کردهاند و جزئیات شرکای تعاملی آنها و مسیرهایی که در آنها فعالیت میکنند را توصیف کردهاند. اما هنوز بسیاری از آنها به طور کامل مشخص نشدهاند. با استفاده از نمایشگرها، ما میتوانیم با دقت بالا برچسبهای ناقص را پیشبینی کنیم.
2- پیشبینی پیوند(Link prediction)
پیشبینی پیوند به وظیفه پیشبینی پیوندهای ناقص یا پیوندهایی که در آینده احتمالاً اتفاق میافتند اشاره دارد. به عنوان مثال در شبکه پروتئین-پروتئین، که تأیید وجود پیوندها بین گرههایی که پروتئینها هستند نیازمند آزمایشهای تجربی هزینهبر است، پیشبینی پیوند میتواند به شما در صرفهجویی در هزینه کمک کند تا فقط در مواردی که شانس حدس درست بیشتری دارید، بررسی کنید.
3- خوشهبندی(Clustering)
خوشهبندی برای یافتن زیرمجموعههایی از گرههای مشابه و گروهبندی آنها استفاده میشود؛ در نهایت، به کمک تصویرسازی، درک بهتری از ساختار شبکه فراهم میشود.
بازگشت به مورد رباتها!!
یک فرضیه میتواند مطرح شود که رباتها تعداد کمی پیوند با کاربران واقعی دارند، زیرا کی کسی میخواهد با آنها دوست شود، اما تعداد زیادی پیوند بین خودشان دارند تا به عنوان کاربران واقعی به نظر برسند. در اینجا، خوشهبندی گراف یا شناسایی اجتماعها وارد عمل میشوند. ما میخواهیم این خوشهها را پیدا کنیم و کاربران ربات را حذف کنیم. این با استفاده از نمایشگرهای گره، به ویژه نمایشگرهای گره پویا که تعاملات در آنها به طور ثانیهای صورت میگیرد، قابل انجام است.
یک مقاله جالب به نام “آمد و رفت رباتهای اجتماعی” وجود دارد که میتوانید در آن بخوانید که چگونه رباتها برای تأثیرگذاری و احتمالاً تلاطم در بحث آنلاین درباره سیاست واکسیناسیون استفاده میشوند.







برای نوشتن دیدگاه باید وارد بشوید.